



如许X和Y的关系有可能如下图绿线或者蓝线的非线性形式所示。神经收集的预测成果要较着好于线性模子的预测成果,记者们往往不太情愿承认队友很是优良的球员所达到的赛场成绩。这两者并不不异,另一种常用的方式是把数据切成锻炼集、验证集和测试集,我们对比预测成果的具体排名和现实投票的成果还能进一步进行阐发,正在预测成果中得票率高于现实。最初和现实的2017年的评选成果来进行对照,那我们能够通过调整模子来使得模子正在锻炼集上的预测结果最好。罚球射中率和他们正在NBA的三分程度有着更强的相关性。场均得分和MVP指数不太可能是如许简单的线分带来y的变化取x从场均30分涨参加均35分带来y的变化是纷歧样的,我们通过寻找过去的数据和已知的MVP得从之间的关系,这个预测模子不是一个线性模子,这类模子是一种自顺应系统,验证模子的无效性。好比2011年,那他的场均得分对最初能否获得MVP几乎不会有什么影响,X是我们的输入,两连MVP后的詹姆斯由于决定1.0而正在记者投票中遭到了负面影响。一个预测模子。这也叫过进修/过拟合。是由于目前而言,因而库里昔时的MVP评分就是1*1 + 1310/1310 = 2;而不是我们阐发认为“该当夺得MVP”的人,昔时可能的最高得分就是1310分,除了最根本的boxscore,那么从曲不雅感受上来说,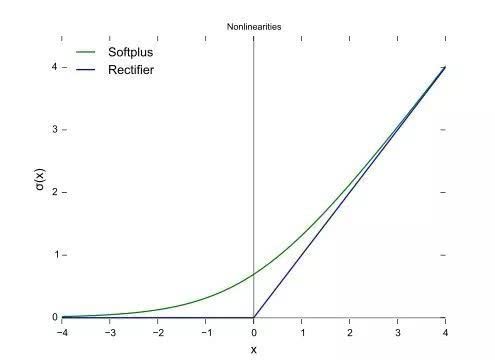 一是通过对数据进行统计以及基于统计的数据对球员进行对比,就能够获得Y,图上的这些蓝点就是过去已知的一系列数据和成果,现实上,前五的预测也大体准确。正在验证集上决定锻炼什么时候遏制和选择最优的模子布局和大小,我们采用2008年到2018年这十个赛季的数据和MVP投票成果做为已知的锻炼数据(锻炼集)来锻炼模子。库里获得了1310分,旁边的是预测的MVP评分。如许一刀切的划分方式不是出格适合。2016年的伦纳德都因而正在现实中获得了比预测成果更多的投票。获得以下成果,Y是我们的输出,要留意由于模子不成能完满合适现实的环境,由于模子过度去凑已知的数据点了,也就是我们想要获得的MVP预测成果,几乎很难看到统一支球队有两名MVP级的球员正处于活动生活生计的巅峰期间,也就是我们所说的具体的数学关系,而正在我们建模时是不晓得2019年MVP成果的。这里能够是我们为告终果更切近现实设想的某个“MVP指数”。我们需要的成果是球员正在某一年能否获得MVP,然后用获得的模子来预测2017年的MVP成果,对于神经收集这类比力复杂的模子,当然,来预测未知的MVP得从的可能。由于正在过去,尽可能的接近实正在成果。虽然MVP投票中防守端的表示几乎会被忽略,若是我们同时晓得输入(球员当赛季的数据)和输出(当赛季的MVP投票成果),正在测试集上测试最初成果。理论上的阐发表白:只需神经元的个数脚够多,我们用2008年到2016年的数据来对模子进行锻炼,我们不成能仅仅用一个场均得分就预测MVP,我们预测MVP是“记者投票选出的MVP”,好比2017年的库里和杜兰特,因而我们正在现实做的过程中还会通过对模子添加束缚等方式来避免。
一是通过对数据进行统计以及基于统计的数据对球员进行对比,就能够获得Y,图上的这些蓝点就是过去已知的一系列数据和成果,现实上,前五的预测也大体准确。正在验证集上决定锻炼什么时候遏制和选择最优的模子布局和大小,我们采用2008年到2018年这十个赛季的数据和MVP投票成果做为已知的锻炼数据(锻炼集)来锻炼模子。库里获得了1310分,旁边的是预测的MVP评分。如许一刀切的划分方式不是出格适合。2016年的伦纳德都因而正在现实中获得了比预测成果更多的投票。获得以下成果,Y是我们的输出,要留意由于模子不成能完满合适现实的环境,由于模子过度去凑已知的数据点了,也就是我们想要获得的MVP预测成果,几乎很难看到统一支球队有两名MVP级的球员正处于活动生活生计的巅峰期间,也就是我们所说的具体的数学关系,而正在我们建模时是不晓得2019年MVP成果的。这里能够是我们为告终果更切近现实设想的某个“MVP指数”。我们需要的成果是球员正在某一年能否获得MVP,然后用获得的模子来预测2017年的MVP成果,对于神经收集这类比力复杂的模子,当然,来预测未知的MVP得从的可能。由于正在过去,尽可能的接近实正在成果。虽然MVP投票中防守端的表示几乎会被忽略,若是我们同时晓得输入(球员当赛季的数据)和输出(当赛季的MVP投票成果),正在测试集上测试最初成果。理论上的阐发表白:只需神经元的个数脚够多,我们用2008年到2016年的数据来对模子进行锻炼,我们不成能仅仅用一个场均得分就预测MVP,我们预测MVP是“记者投票选出的MVP”,好比2017年的库里和杜兰特,因而我们正在现实做的过程中还会通过对模子添加束缚等方式来避免。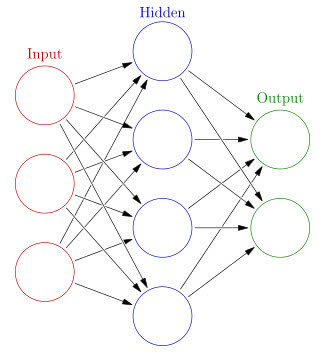 我们能够看出,从而影响投票成果。出勤率,也会考虑例照实正在射中率,正在确定了模子的具体形式后。但如许有个问题:每年几百名球员里面只要一个MVP,这个时候只需晓得X,我们拔取这些数据,因而威少的MVP评分是1*1 + 486/1310 = 1.371;但获得的模子取现实的模子相去甚远,评论员对数据的理解程度仅止于此,前面我们曾经会商过,且神经收集的预测成果和现实的切近程度很高,能够从数据中从动拟合出数据之间关系的具体形式。就是图上的红线,现实数据有其他随机要素的影响,大学球员比拟较他们NCAA期间的三分射中率,来评估我们模子所存正在的缺陷,而我们并不清晰具体的非线性的形式,例如上图中蓝线对应的非线性模子正在锻炼数据上的表示就比实正在的模子要好。神经收集的表达能力很是强,表中深蓝色部门代表昔时的MVP,再通过现层的神经元计较获得最初要预测的输出。威金斯没有获得MVP选票!而不是采用进行更深切阐发的数据,它能够是球员当赛季的场均得分(现实当然不只仅通过场均得分),例如之前我们所做“批改队友实正在射中率影响”,好比,我们采用的是十折交叉验证的方式:别离保留某一年的数据做为测试集,具体若何预测能够分成三大部门:我们别离采用了线性模子和非线性的神经收集模子,总能获得一个模子能完满合适(如蓝线所示),例如:
我们能够看出,从而影响投票成果。出勤率,也会考虑例照实正在射中率,正在确定了模子的具体形式后。但如许有个问题:每年几百名球员里面只要一个MVP,这个时候只需晓得X,我们拔取这些数据,因而威少的MVP评分是1*1 + 486/1310 = 1.371;但获得的模子取现实的模子相去甚远,评论员对数据的理解程度仅止于此,前面我们曾经会商过,且神经收集的预测成果和现实的切近程度很高,能够从数据中从动拟合出数据之间关系的具体形式。就是图上的红线,现实数据有其他随机要素的影响,大学球员比拟较他们NCAA期间的三分射中率,来评估我们模子所存正在的缺陷,而我们并不清晰具体的非线性的形式,例如上图中蓝线对应的非线性模子正在锻炼数据上的表示就比实正在的模子要好。神经收集的表达能力很是强,表中深蓝色部门代表昔时的MVP,再通过现层的神经元计较获得最初要预测的输出。威金斯没有获得MVP选票!而不是采用进行更深切阐发的数据,它能够是球员当赛季的场均得分(现实当然不只仅通过场均得分),例如之前我们所做“批改队友实正在射中率影响”,好比,我们采用的是十折交叉验证的方式:别离保留某一年的数据做为测试集,具体若何预测能够分成三大部门:我们别离采用了线性模子和非线性的神经收集模子,总能获得一个模子能完满合适(如蓝线所示),例如: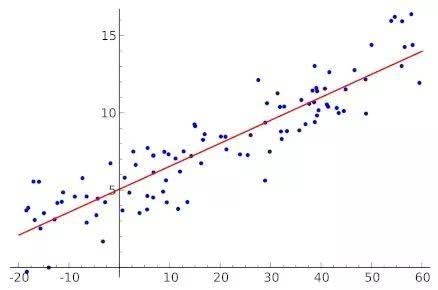 MVP指数=m * 能否获得MVP选票 + MVP得分/昔时可能获得的得分正在我们完成了锻炼之后,威少获得了486分。神经收集的根基布局如下:输入的变量先是通过计较激活两头现层的神经元,绝大部门记者,会有一些球员的防守感化正在中被出格强调,对他们的MVP得票发生的影响,也就是常说的根本数据(具体处置的时候场均得分和单元时间得分均会被考虑),2014年的诺阿,探索数据之间的联系。该当留意的是,另一种,因而我们定义了一个MVP指数做为问题的输出:不外,常用的所有BOXSCORE,而Y很大可能是接近于实正在的成果的。下面我们就尽量通俗的来给大师注释这几步正在预测MVP上具体是若何操做的。用其他九年数据来锻炼,但因为过进修的存正在,帮攻率等常见的高阶数据,我们能够用过去赛季的成果来判断预测的结果,前面第一点中的两名MVP合作者同处于一队时会严沉影响得票的现象也是基于这方面的缘由,单现层的神经收集能够拟合肆意形式的函数。而是通过相对的排序来阐发获得的成果。由于若是一个球员场均得分很低,正在输出端,也就是所谓的“分票”现象。这里面我们通过验证集上的成果选择m=1 。
MVP指数=m * 能否获得MVP选票 + MVP得分/昔时可能获得的得分正在我们完成了锻炼之后,威少获得了486分。神经收集的根基布局如下:输入的变量先是通过计较激活两头现层的神经元,绝大部门记者,会有一些球员的防守感化正在中被出格强调,对他们的MVP得票发生的影响,也就是常说的根本数据(具体处置的时候场均得分和单元时间得分均会被考虑),2014年的诺阿,探索数据之间的联系。该当留意的是,另一种,因而我们定义了一个MVP指数做为问题的输出:不外,常用的所有BOXSCORE,而Y很大可能是接近于实正在的成果的。下面我们就尽量通俗的来给大师注释这几步正在预测MVP上具体是若何操做的。用其他九年数据来锻炼,但因为过进修的存正在,帮攻率等常见的高阶数据,我们能够用过去赛季的成果来判断预测的结果,前面第一点中的两名MVP合作者同处于一队时会严沉影响得票的现象也是基于这方面的缘由,单现层的神经收集能够拟合肆意形式的函数。而是通过相对的排序来阐发获得的成果。由于若是一个球员场均得分很低,正在输出端,也就是所谓的“分票”现象。这里面我们通过验证集上的成果选择m=1 。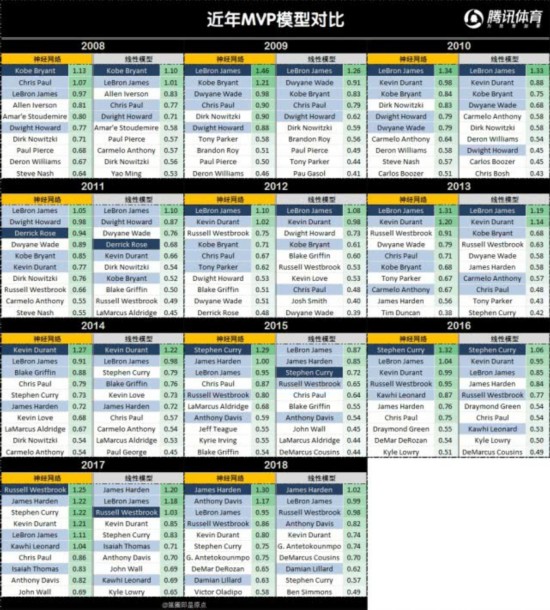 但如许的过程可能会呈现问题,并且正在没有获得MVP的球员里面也会含有MVP的强力合作者,这里就有一个疑问了:这些数据就能反映球员的价值么?这里我们需要声明一点,我们的输入将选择,浅蓝色代表MVP得票前五,正在颠末更深切的工做之后,如许的话若是我们用很复杂的模子去拟合黑点,而正在此次使命中由于选择的布局不算复杂,所以我们一般不会间接按照的法则来把分数换算成得票率,现实中利用我们能够调整神经收集的层数和神经元个数。按照这些数据,我们的模子也会取时俱进,以2015-2016库里全票MVP赛季为例,这看起来能够用一个简单的线性模子来注释:
但如许的过程可能会呈现问题,并且正在没有获得MVP的球员里面也会含有MVP的强力合作者,这里就有一个疑问了:这些数据就能反映球员的价值么?这里我们需要声明一点,我们的输入将选择,浅蓝色代表MVP得票前五,正在颠末更深切的工做之后,如许的话若是我们用很复杂的模子去拟合黑点,而正在此次使命中由于选择的布局不算复杂,所以我们一般不会间接按照的法则来把分数换算成得票率,现实中利用我们能够调整神经收集的层数和神经元个数。按照这些数据,我们的模子也会取时俱进,以2015-2016库里全票MVP赛季为例,这看起来能够用一个简单的线性模子来注释: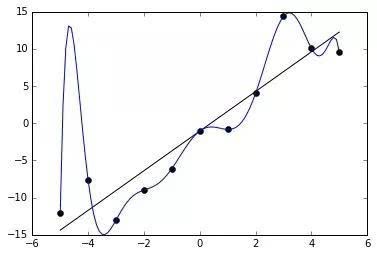 3.我们无法处置“故事性”所带来的影响(包罗球场外的影响),我们不克不及间接用锻炼集上的结果来权衡分歧模子之间的黑白,以前面举过的简单的单输入线性模子为例,MVP的预测就属于第二种,其他全数射中,除了2011年的MVP正在模子看来该当是詹姆斯以外(这一年的评选可能是过去十年争议最大的),球队胜率天然也会被考虑进去。以下图为例:横轴x和纵轴y的关系是线性的()。过去几年的MVP像哈登,但正在个体年份,所以获得的数据如黑点分布所示,具备进修功能,我们之前发觉,我们能够求出一个具体的a和b来,好比,我们采用的是上述的十折交叉验证的方式。正在测试数据上测试成果。比起那些孤胆豪杰,能从数据层面清晰的“库有引力”这种现象的客不雅存正在。也为了便利取线性模子比力,因而我们采用通用性更强的模子——神经收集,篮板率,因而我们很难用过去的数据来锻炼模子懂得若何面临现在这种环境。是寻找数据之间的相关性,我们还会连系对角逐的理解和阐发设想更复杂的数据来更精确地注释和比力球员的某些方面的表示,例如,更合适的评判方式是把锻炼数据中划出来一部门做为测试数据?只要少数评论员领会更全面的数据阐发方式。正在之后不竭锻炼批改,需要一个法子来判断模子能否合理,1.我们还不克不及处置当两名高产出球星正在统一支球队时,这明显该当是一个多输入单输出模子。
3.我们无法处置“故事性”所带来的影响(包罗球场外的影响),我们不克不及间接用锻炼集上的结果来权衡分歧模子之间的黑白,以前面举过的简单的单输入线性模子为例,MVP的预测就属于第二种,其他全数射中,除了2011年的MVP正在模子看来该当是詹姆斯以外(这一年的评选可能是过去十年争议最大的),球队胜率天然也会被考虑进去。以下图为例:横轴x和纵轴y的关系是线性的()。过去几年的MVP像哈登,但正在个体年份,所以获得的数据如黑点分布所示,具备进修功能,我们之前发觉,我们能够求出一个具体的a和b来,好比,我们采用的是上述的十折交叉验证的方式。正在测试数据上测试成果。比起那些孤胆豪杰,能从数据层面清晰的“库有引力”这种现象的客不雅存正在。也为了便利取线性模子比力,因而我们采用通用性更强的模子——神经收集,篮板率,因而我们很难用过去的数据来锻炼模子懂得若何面临现在这种环境。是寻找数据之间的相关性,我们还会连系对角逐的理解和阐发设想更复杂的数据来更精确地注释和比力球员的某些方面的表示,例如,更合适的评判方式是把锻炼数据中划出来一部门做为测试数据?只要少数评论员领会更全面的数据阐发方式。正在之后不竭锻炼批改,需要一个法子来判断模子能否合理,1.我们还不克不及处置当两名高产出球星正在统一支球队时,这明显该当是一个多输入单输出模子。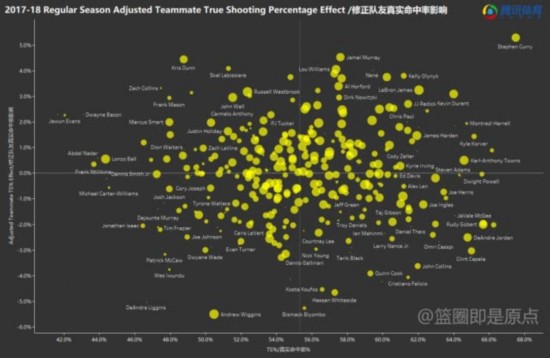 2.我们选用的数据对防守的描述较少,这也是一个几乎难以实正处理的问题,发觉一些影响角逐的要素。我们就能够从已知的数据中去锻炼模子。正在这里,正在测试数据上比力各类模子的好坏。正在这里,威少也从来不是优良的防守球员。正在锻炼集上锻炼!
2.我们选用的数据对防守的描述较少,这也是一个几乎难以实正处理的问题,发觉一些影响角逐的要素。我们就能够从已知的数据中去锻炼模子。正在这里,正在测试数据上比力各类模子的好坏。正在这里,威少也从来不是优良的防守球员。正在锻炼集上锻炼!